Layers & Modules
This chapter gives an overview how the Agent standard and Kit should be implemented in terms of layers and modules.
For more information see
- Our Adoption guideline
- The High-Level Architecture
- The Ontology modelling guide
- The ARC42 documentation
- An API specification
- Our Reference Implementation
- The Deployment guide
In this context generic building blocks were defined (see next figure) which can be implemented with different open source or COTS solutions. In the scope of Catena-X project these building blocks are instantiated with a reference implementation based on open source components (the Knowledge Agents KIT). The detailed architecture following this reference implementation can be found here.
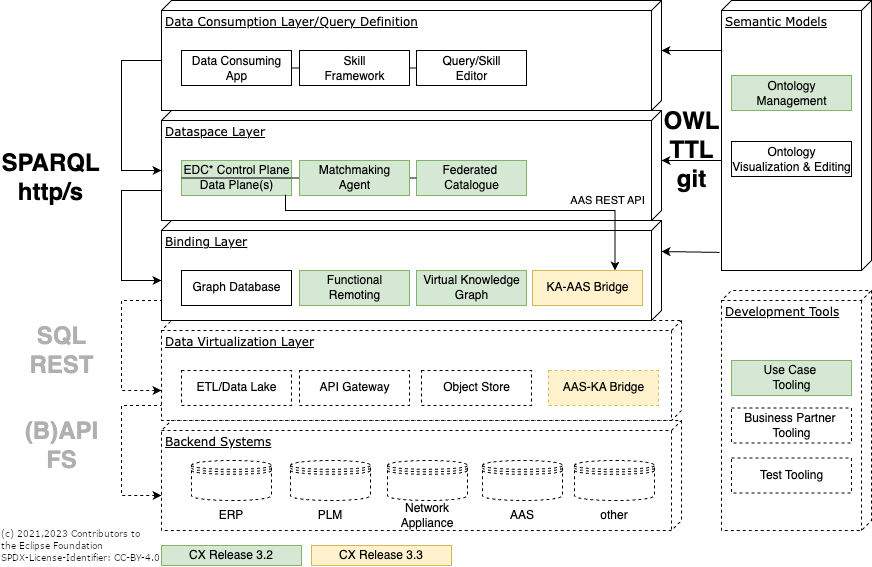
In the following paragraphs, all building blocks relevant for this standard are introduced:
Semantic Models
Ontologies, as defined by W3C Web Ontology Language OWL 2 standard, provide the core of the KA catalogue. By offering rich semantic modelling possibilities, they contribute to a common understanding of existing concepts and their relations across the data space participants. To increase practical applicability, this standard contains an overview about most important concepts and best practices for ontology modelling relevant for the KA approach (see chapter 5). OWL comes with several interpretation profiles for different types of applications. For model checking and data validation (not part of this standard), this KIT proposes the Rule Logic (RL) profile. For query answering/data processing (part of this standard), this KIT applies the Existential Logic (EL) profile (on the Dataspace Layer) and the Query Logic (QL) profile (on the Binding Layer).
Ontology Editing & Visualization
To create and visualize ontology models, dedicated tooling is advised. For this purpose, various open source tools (e.g. Protegé) or commercial products (e.g. metaphacts) are available. This KIT hence standardizes on the ubiquitous RDF Terse Triple Language TTL format which is furthermore able to divide/merge large ontologies into/from modular domain ontology files.
Ontology Management
To achieve model governance, a dedicated solution for ontology management is necessary. Key function is to give an overview about available models and their respective meta data and life cycle (e.g. in work, released, deprecated). Because of the big parallels, it is today best practice to perform ontology management through modern and collaborative source code versioning systems. The de-facto standard in this regard is GIT (in particular: its http/s protocol variant, including an anonymous read-only raw file access to release branches). In the following, we call the merged domain ontology files in a release branch “the” (shared) Semantic Model (of that release). For practicability purposes, the Data Consumption and the Binding Layer could be equipped with only use-case and role-specific excerpts of that Semantic Model. While this may affect the results of model checking and validity profiles, it will not affect the query/data processing results.
Data Consumption Layer/Query Definition
This layer comprises all applications which utilize provided data and functions of business partners to achieve a direct business impact and frameworks which simplify the development of these applications. Thus, this layer focuses on using a released Semantic Model (or a use-case/role-specific excerpt thereof) as a vocabulary to build flexible queries (Skills) and integrating these Skills in data consuming apps.
This KIT relies on SPARQL 1.1 specification as a language and protocol to search for and process data across different business partners. As a part of this specification, this KIT supports the QUERY RESULTS JSON and the QUERY RESULTS XML formats to represent both the answer sets generated by SPARQL skills and the sets of input parameters that a SPARQL skill should be applied to. For answer sets, additional formats such as the QUERY RESULTS CSV and TSV format may be supported. Required is the ability to store and invoke SPARQL queries as parameterized procedures in the dataspace; this is a KA-specific extension to the SPARQL endpoint and is captured a concise Openapi specification. Also part of that specification is an extended response behaviour which introduces the warning status code “203” and a response header “cx_warning” bound to a JSON structure that lists abnormal events or trace information that appeared during the processing.
Skill Framework
Consumer/Client-side component, which is connected to the consumer dataspace components (the Matchmaking Agent via SPARQL, optionally: the EDC via the Data Management API). It is at least multi-user capable (can switch/lookup identities of the logged-in user), if not multi-tenant capable (can switch Matchmaking Agents and hence ED Connectors). It looks up references to Skills in the Dataspace and delegates their execution to the Matchmaking Agent. The Skill framework may maintain a “conversational state” per user (contextual memory which is a kind of graph/data set) which drives the workflow. It may also help to define, validate and maintain Skills in the underlying Dataspace Layer.
Query/Skill Editor
To systematically build and maintain Skills, a query editor for easy construction and debugging queries is advisable. The skill editor should support syntax highlighting for the query language itself and it may support auto-complete based on the Semantic Model. A skill editor could also have a graphical model in which a procedure can be composed out of pre-defined blocks. Finally, a skill editor should have the ability to test-drive the execution of a skill (maybe without storing/publishing the skill and making any “serious” contract agreements in the dataspace and based on sample data).
Data Consuming App
Application that utilizes data of data providers to deliver added value to the user (e.g. CO2 footprint calculation tool). Skills can be easily integrated in these apps as stored procedure. Hence, skill and app development can be decoupled to increase efficiency of the app development process. For more flexible needs, Skills could be generated ad-hoc from templates based on the business logic and app data. The Data Consuming App could integrate a Skill Framework to encapsulate the interaction with the Dataspace Layer. The Consuming App could also integrate a Query/Skill Editor for expert users.
Dataspace Layer
The base Dataspace-building technology is the Eclipse Dataspace Connector (EDC) which should be extended to operate as a HTTP/S contracting & transfer facility for the SPARQL-speaking Matchmaking Agent. To resolve dataspace offers and addresses using the ontological vocabulary, the Matchmaking Agent keeps a default meta-graph, the Federated Catalogue, that is used to host the Semantic Model and that is regularly synchronized with the relevant dataspace information including the offers of surrounding business partners/EDCs.
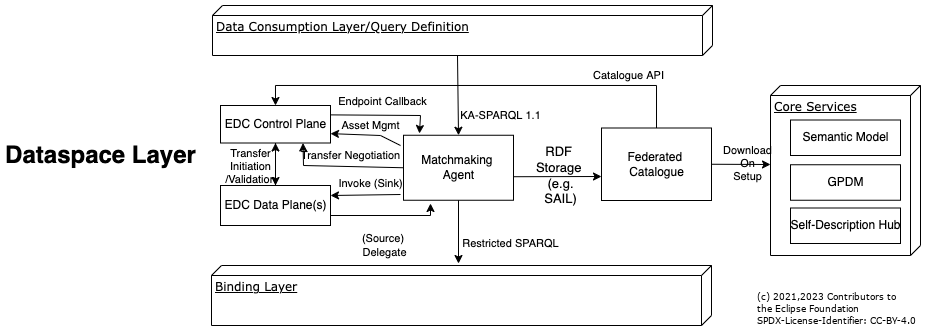
EDC
Actually, the Eclipse Dataspace Connector (see Catena-X Standard CX-00001) consists of two components, one of which needs to be extended. See the Tractus-X Knowledge Agents EDC Extensions (KA-EDC) and their KA-EDC Deployment
Control Plane
The Control Plane hosts the actual management/negotiation engine and is usually a singleton that is exposing
- an internal (api-key secured) API for managing the control plane by administrative accounts/apps and the Matchmaking Agent
- Manages Assets (=Internal Addresses including security and other contextual information into the Binding/Virtualization/Backend Layers together with External meta-data/properties of the Assets for discovery and self-description)
- Manages Policies (=Conditions regarding the validity of Asset negotiations and interactions)
- Manages Contract Definitions (=Offers are combinations of Assets and Policies and are used to build up a Catalogue)
- a public (SSI-secured) Protocol API for coordination with other control planes of other business partners to setup transfer routings between the data planes.
- state machines for monitoring (data) transfer processes which are actually executed by the (multiple, scalable) data plane(s). KA uses the standard “HttpProxy” transfer.
- a validation engine which currently operates on static tokens/claims which are extracted from the transfer flow but may be extended with additional properties in order to check additional runtime information in the form of properties
- callback triggers for announcing transfer endpoints to the data plane to external applications, such as the Matchmaking Agent (or other direct EDC clients, frameworks and applications). This KIT supports multiple Matchmaking Agent instances per EDC for load-balancing purposes and it also allows for a bridged operation with other non-KA use cases, so it should be possible to configure several endpoint callback listeners per control plane.
Data Plane
The Data Plane (multiple instances) performs the actual data transfer tasks as instrumented by the control plane. The data plane exposes transfer-specific capabilities (Sinks and Sources) to adapt the actual endpoint/asset protocols (in the EDC standard: the asset type).
Graph Assets use the asset type/data source “urn:cx:Protocol:w3c:Http#SPARQL”. In their address part, the following properties are supported
| Data Address Property | Description |
|---|---|
| @type | must be set to "DataAddress" |
| type | Must be set to "cx-common:Protocol?w3c:http:SPARQL" |
| id | The name under which the Graph will be offered. Should be a proper IRI/URN, such as GraphAsset?oem=BehaviourTwin |
| baseUrl | The endpoint URL of the binding agent (see below). Should be a proper http/s SPARQL endpoint. |
| proxyPath | must be set to “false” |
| proxyMethod | must be set to “true” |
| proxyQueryParams | must be set to “true” |
| proxyBody | must be set to “true” |
| authKey | optional authentication header, e.g. “X-Api-Key” |
| authCode | optional authentication value, such as an API key |
| header:Accepts | optional fixes the Accepts header forwarded to the endpoint, e.g., “application/sparql-results+json” |
| cx-common:allowServicePattern | an optional regular expression that overrides the default service URL allowance (white list) for this asset |
| cx-common:denyServicePattern | an optionaal regular expression that overrides the default service URL denial (black list) for this asset |
Skill Assets use the asset type/data source “urn:cx:Protocol:w3c:Http#SKILL”. In their address part, the following properties are supported
| DataAddress Property | Description |
|---|---|
| @type | must be set to "DataAddress" |
| type | Must be set to "cx-common:Protocol?w3c:http:SKILL" |
| id | The name under which the Skill will be offered. Should be a proper IRI/URN, such as SkillAsset?supplier=RemainingUsefulLife |
| baseUrl | The endpoint URL of the binding agent (see below). Should be a proper http/s SPARQL endpoint. |
| proxyPath | must be set to “false” |
| proxyMethod | must be set to “true” |
| proxyQueryParams | must be set to “true” |
| proxyBody | must be set to “true” |
Both Skill and Graph Assets share public properties
| Public Property | Description |
|---|---|
| @type | must be set to "Asset" |
| @id | The name under which the Skill/Graph will be offered. Should coincide with the "id" in the DataAddress |
| properties.name | Title of the asset in the default language (English). |
| properties.name@de | Title of the asset in German (or other languages accordingly). |
| properties.description | Description of the asset in the default language (English) |
| properties.description@de | Description of the asset in German (or other languages accordingly). |
| properties.version | A version IRI |
| properties.contenttype | "application/json, application/xml" for Graph Assets, "application/sparql-query, application/json, application/xml" for Skill Assets |
| properties.rdf:type | "cx-common:GraphAssetAsset" for graph Assets, "cx-common:SkillAsset" for Skill Assets |
| properties.rdfs:isDefinedBy | An RDF description listing the Use case ontologies that this asset belongs to, e.g., “<https://w3id.org/catenax/ontology/core>" |
| properties.cx-common:implementsProtocol | should be set to “<urn:cx:Protocol:w3c:Http#SPARQL>��” for Graph Assets, “<urn:cx:Protocol:w3c:Http#SKILL>” for Skill Assets |
| properties.cx-common:isFederated | Whether this asset will be automatically synchronized (and is hence inferrable) in the federated data catalogue |
Graph Assets have the following public properties
| Public Property | Description |
|---|---|
| properties.sh:shapesGraph | A turtle string describing the shape of the offered Graph Asset in the SHACL constraint language. |
Skill Assets have the following public properties
| Public Property | Description |
|---|---|
| properties.cx-common:distributionMode | Determines where the SKILL is actually executed; "cx-common:SkillDistribution?run=provider" needs to be executed at the provider (agent/EDC). "cx-common:SkillDistribution?run=consumer" needs to be execute at the consumer (agent/EDC), "cx-common:SkillDistribution?run=all" allows both executions. |
Skill Assets have the following private properties
| Private Property | Description |
|---|---|
| privateProperties.cx-common:query | A SPARQL string implementing the skill. |
For both Graph and Skill Assets, appropriate Sink and Source implementations have to be registered which operate just as the standard HttpSink and HttpSource, but cater for some additional peculiarities. In particular, the “AgentSource”
- will detunnel all protocol-specific information from the HttpProxy call (headers wrapped as parameters etc., see the standard).
- may parse the query and validate the given data address using additional runtime information from the query, the header, the parameters and extended policies with the help of the extended control plane.
- rewrites the resulting SPARQL query parameter/body by replacing any occurrence of the Asset-URI
GRAPH <?assetUri>with the actual URL of the asset baseUrlSERVICE <?baseUrl>. - may rewrite the query using the “sh:shape” property of the GraphAsset in order to enforce particular constraints.
- finally delegate the resulting call to the Matchmaking Agent.
Matchmaking Agent
This component which is the first stage of SPARQL processing serves several purposes. It operates as the main invocation point to the Data Consuming Layer. It operates as the main bridging point between incoming EDC transfers (from an “Agent Source”) and the underlying Binding Layer. And it implements federation by delegating any outgoing SERVICE/GRAPH contexts to the EDC. The Matchmaking Agent
- Should perform a realm-mapping from the tenant domain (Authentication Scheme, such as API-Key and Oauth2) into the dataspace domain (EDC tokens)
- Should use the EDC management API in order to negotiate outgoing “HttpProxy” transfers. It may use parallelism and asynchronity to perform multiple such calls simultaneously. It will wrap any inbound “Accept” header requirements as an additional “cx_accept” parameter to the transfer sink.
- Should operate as a endpoint callback listener, such that the setup transfers can invoke the data plane
- Uses and Maintains the Federated Catalogue as an RDF store.
- Should be able to access Binding Agents by means of “SERVICE” contexts in the SPARQL standard. Hereby, the Matchmaking Agent should be able to restrict the type of sub-queries that are forwarded. For practicability purposes, Binding Agents need only support a subset of SPARQL and OWL (no embedded GRAPH/SERVICE contexts, no transitive closures and inversion, no object variables in rdf:type, no owl:sameAs lookups, …).
Since EDC and Matchmaking Agent are bidirectionally coupled, implementations could merge Data Plane and Matchmaking Agent into a single package, the so-called Agent Plane. Agent Planes and ordinary Data Planes can co-exist due to our design choices.
Federated Catalogue
The Federated Catalogue is an RDF data storage facility for the Matchmaking Agent. It could be an in-memory triple store (that is restored via downloading TTL and configuration files upon restart) or an ordinary relational database that has been adapted to fit to the chosen Matchmaking Agent implementation. One example of such an interface is the RDF4J SAIL compliant to all RDF4J based SPARQL engines.
The Federated Catalogue should initially download the complete Semantic Model that has been released for the target environment. It should also contain a list of business partners and their roles which form the surrounding dataspace neighborhood of the tenant. For that purpose, It could use GPDM (Business Partner Data Management) and Self-Description Hub services in order to lookup EDC addresses and additional domain information (sites, geo addresses). It should then be frequently updated with “live” information by invoking the EDC data management API to regularly obtain catalogue information.
The portion of the Semantic Model describing these meta-data (Business Partners, Sites, Addresses, Use Cases, Use Case Roles, Connectors & Assets) is called the Common domain ontology and is mandatory for all releases/excerpts of the Semantic Model .
Virtualization Layer (Non-Standard Relevant)
The data virtualization layer fulfills the function of making the company internal, department-hosted data available for cross-company data exchange scenarios, e.g. via data lakes, data warehouses or other enterprise middleware.
Instead of connecting each and every backend system separately to an published data source/sink (such as provided by Catena-X) it often makes sense to have this additional layer on top of backend systems which orchestrates data demand and supply across the systems.
Depending on company IT architecture different technologies can be used to build up this layer.
ETL/Data Lakes
In this scenario data from connected backend systems is stored in a central repository, such as in a Data Lake or central Data Warehouse scenario. Here, different kinds of raw data can be stored, processed, and combined to new data sets, while still being centrally available for any access. Synchronization between backends and data lake is achieved via ETL processes.
API Gateway
This approach offers users a unified and technically abstract view for querying and manipulating data across a range of disparate sources. As such, it can be used to create virtualized and integrated views of data in memory rather than executing data movement and physically storing integrated views.
Binding Layer
Finally, the missing link between the Dataspace Layer and the Virtualization Layer is the Binding Layer. Hereby rather than mapping the data between different formats (e.g. Data Tables in CSV Format to and from Data Graphs in the TTL format) which is a mostly resource-consuming data transformation process, binding rather rewrites the actual queries (e.g. SPARQL into SQL, SPARQL into GraphQL or REST). In order to make this query rewriting not too complicated, a restricted subset of SPARQL is envisaged.
See the Tractus-X Knowledge Agents Reference Implementations (KA-RI) and their KA-RI Deployment
Virtual Knowledge Graph
A Virtual Knowledge Graph has the aim to make the content of relational databases accessable as a virtual knowledge graph. Virtual in this context means that the data itself remains in the relational database. Furthermore, this building block provides the function to translate SPARQL to SQL queries (e.g. via R2RML mappings in TTL).
Functional Remoting
The Functional Remoting building block allows translation of SPARQL queries to specific API calls, e.g. to trigger a certain computation function. Function Binding is described in a special RDF4J TTL configuration.
Graph Database
A graph database stores a pre-mapped Knowledge Graph in a dedicated RDF store. It can be combined with a Virtual Knowledge Graph in order to cache frequent accesses to the Virtualization Layer.
AAS Bridge(s)
These are virtualization components which bridge between the Semantic Web technology of Knowledge Agents with the Industrial Digital Twin Association's Asset Administration Shell (AAS) standard.
Actually, this KIT is caring about two bridges, one which bridges AAS information that is described in Catena-X aspect schemas into the Catena-X domain ontologies (the AAS-KA Bridge). And one bridge which is able to emulate shells and submodels out of a given (federated) virtual graph (the SPARQL-AAS Bridge).
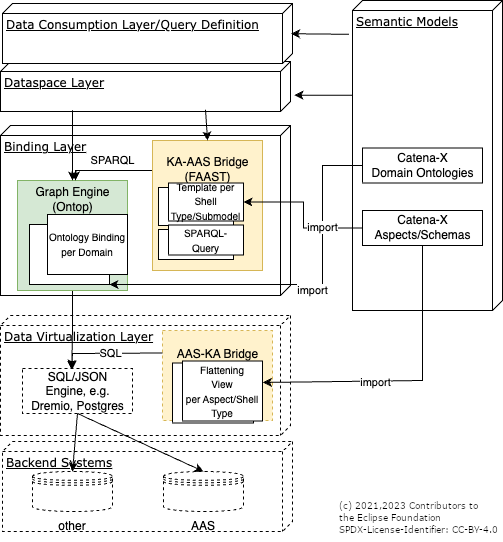
As the result, we are able to provide both SPARQL-based Graph Assets as well as AAS-based Submodel Assets based on the same data sources.
This integration does not aim to solve the fundamental challenge of conflicting data formats on the meta-model level but maps only a subset of the domain-models between the Knowledge-Graph- and AAS-world. This is true for either direction: The native submodel template/aspect model must be mapped to a subset of the Catena-X-Ontology manually. Likewise, only that part of the graph can be exposed via the AAS-APIs that has mapper implementing the transformation.
AAS->KA Bridge
Special form of virtualization component which denormalizes/flattens & caches the often hierarchical information (Shells, Submodels, Submodel Elements) stored in backend AAS servers in order to make it accessible for ad-hoc querying.
There are two main components whose interplay implements the AAS-KA bridge:
- A flexible SQL/JSON engine, such as Dremio or in parts also Postgresql which is able to mount raw data in various formats from remote filesystems and APIs. This engine is used to build flat relational views onto a hierarchical json structure that may originate in the value-only-serialization of the AAS. Typically there will be one table/view per json-schema/submodel template. As an example, see these scripts
- A graph engine (such as ontop ) that is able to bind/translate SPARQL queries into SQL. As an example, see these bindings
Of course, if the data is available in a native SQL-schema, the SQL/JSON-engine can be omitted. Likewise, even the graph engine can be left out if a sparql-capable database holds its data in conformance to the CX-ontologies.
SPARQL->AAS Bridge
In order to form a twin-based, highly-standarized access to any graphTo allow for a more strict In order to form a graph-based, flexible access to AAS backend components, we employ a bridge virtualization module which denormalizes/caches the information inside Shells and Submodels.
Exposing substructures of the distributed knowledge graph via the AAS APIs is possible by deploying the KA-AAS-Bridge and its KA-AAS Deployment. This generic tool can be used to expose the graphs structures as AAS by configuring a set of mappings. Each consists of two components
- a SPARQL query extracting "flat" information out of the virtual graph
- a mapping configuration providing the basic structure of the target AAS
These two components must be closely coordinated with each other. The query is executed against an internal SPARQL-endpoint configured by the data provider. Its response (XML) is then digested by the aas4j-transformation-library and transformed into AAS-native structures. This is executed at runtime whenever a request hits the AAS-APIs of the bridge so that the ground truth remains in the RDF-graph (or the persistence it was virtualized from, see above). FAAAST framework provides the AAS-tooling required for the implementation of all relevant AAS-APIs. The library ships with four default mappings for Traceability-related Aspect-Models but is not restricted to these. Details on the KA-AAS-bridge's deployment can (soon) be found in its documentation.
Backend Systems (Non-Standard Relevant)
(Legacy, Non-Dataspace) IT landscape of data space participants consisting of various backend systems, such as PLM, ERP, ObjectStores mostly located in the Enterprise Intranet and hosted/goverened by the business departments. Here, the actual data sources of all Catena-X participants is originated where they are served using custom, but mission-critical business or technological APIs in specific, transaction-oriented formats.
AAS Servers and Databases
As a special case of backend systems, this KIT also regards existing AAS servers and databases as valid data sources to form a semantic dataspace.
(C) 2021 Contributors to the Eclipse Foundation. SPDX-License-Identifier: CC-BY-4.0